字符串 #
我们知道C语言中的字符串是使用字符数组 char[] 表示,字符数组的最后一位元素是 \0,用来标记字符串的结束。C语言中字符串的结构简单,但获取字符串长度时候,需要遍历字符数组才能完成。
Go语言中字符串的底层结构中也包含了字符数组,该字符数组是完整的字符串内容,它不同于C语言,字符数组中没有标记字符串结束的标记。为了记录底层字符数组的大小,Go语言使用了额外的一个长度字段来记录该字符数组的大小,字符数组的大小也就是字符串的长度。
数据结构 #
Go语言字符串的底层数据结构是 reflect.StringHeader(
reflect/value.go),它包含了指向字节数组的指针,以及该指针指向的字符数组的大小:
type StringHeader struct {
Data uintptr
Len int
}
字符串复制 #
当将一个字符串变量赋值给另外一个变量时候,他们 StringHeader.Data 都指向同一个内存地址,不会发生字符串拷贝:
a := "hello"
b := a

从上图中我们可以看到a变量和b变量的Data字段存储的都是0x1234,而0x1234是字符数组的起始地址。
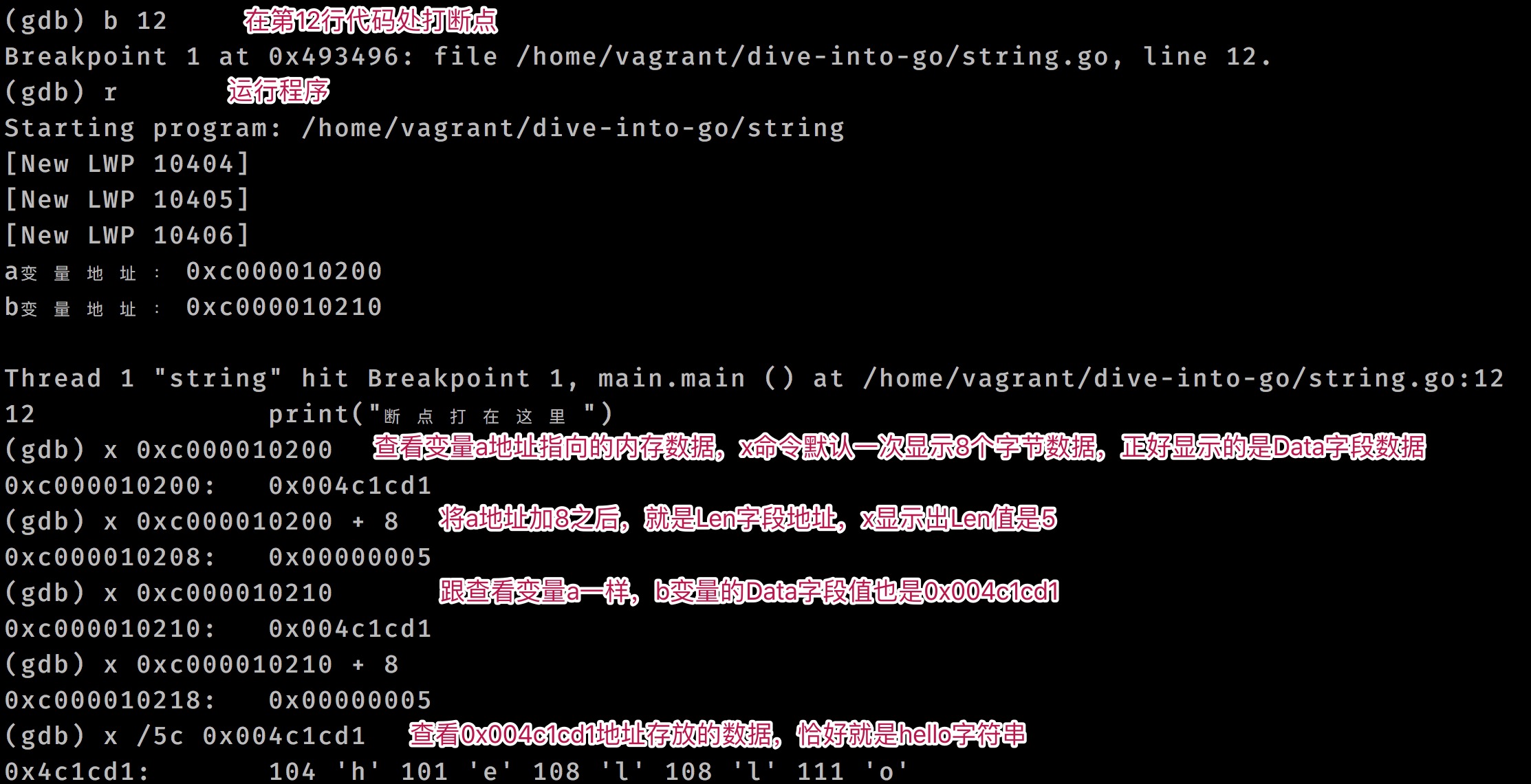
接来下我们借助 GDB 工具来验证Go语言中字符串数据结构是不是按照上面说的那样。
package main
import (
"fmt"
)
func main() {
a := "hello"
b := a
fmt.Printf("a变量地址:%p\n", &a)
fmt.Printf("b变量地址:%p\n", &b)
print("断点打在这里")
}
将上面代码构建二进制应用, 然后使用 GDB 调试一下:
go build -o string string.go # 构建二进制应用
gdb ./string # GDB调试
调试流程如下:
len(str) == 0 和 str == ""有区别吗? #
判断一个字符串是否是空字符串,我们既可以使用len判断其长度是0,也可以判断其是否等于空字符串 ""。那么它们有什么区别吗?这个问题的答案是二者没有区别。因为他们底层实现是一样的。
让我们来探究一下。源代码如下:
package main
func isEmptyStr(str string) bool {
return len(str) == 0
}
func isEmtpyStr2(str string) bool {
return str == ""
}
func main() {
}
接下来我们来查看下上面代码的底层汇编:
go tool compile -S empty_string.go # 查看底层汇编代码
从下图中,我们可以发现两种方式的实现是一样的:
![]()
注意:
当我们编译时候开启了禁止内联,禁止优化时候,可以发现len(str) == 0和str == ""的实现是不同的,前者的执行效率是不如后者的。在默认情况下,Go编译器是开启了优化选项的,len(str) == 0会优化成跟str == ""的实现一样。
[3]string类型的变量占用多大空间? #
对于这个问题,直觉上觉得[3]string类型变量,由3个字符串组成,而字符串长度是不确定的,所以对于类似[n]string类型变量占用多大的空间是不确定。
首先明确的是Go语言中提供了 unsafe.Sizeof 函数来确定一个类型变量占用空间大小,这个大小是不含它引用的内存大小。比如某结构体中一个字段是个指针类型,这个字段指向的内存是不计算进去的,只会计算该字段本身的大小。
字符串底层结构是 reflect.StringHeader ,一共占用16个字节空间,所以我们对于[n]string的大小,计算伪代码如下:
unsafe.Sizeof([n]string) == n * 16
那么问题[3]string类型的变量占用多大空间?的答案是48。
如何高效的进行字符串拼接? #
字符串进行拼接有多种方法:
-
使用拼接字符
+拼接字符串效率低,每次拼接会产生临时字符串,适合少量字符串拼接。使用起来最简单。
-
使用
fmt.Printf()来拼接字符由于需要将字符串转换成空接口类型,效率差,这里面不再讨论
-
使用
strings.Join()来拼接字符串其底层其实使用的是
strings.Builder,效率高,适合字符串数组。 -
使用
bytes.Buffer来拼接字符串效率高,可以复用
-
使用
strings.Builder来拼接字符串效率高,每次Reset()之后,其底层缓冲会被清除,不适合复用。
使用拼接符 + 进行拼接 #
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
strSlices := []string{"h", "e", "l", "l", "o"}
var all string
for _, str := range strSlices {
all += str
sh := (*reflect.StringHeader)(unsafe.Pointer(&all))
fmt.Printf("str地址:%p,all地址:%p,all底层字节数组地址=0x%x\n", &str, &all, sh.Data)
}
}
上面代码输出一下内容:
str地址:0xc000010250,all地址:0xc000010240,all底层字节数组地址=0x4bc8f7
str地址:0xc000010250,all地址:0xc000010240,all底层字节数组地址=0xc000018048
str地址:0xc000010250,all地址:0xc000010240,all底层字节数组地址=0xc000018068
str地址:0xc000010250,all地址:0xc000010240,all底层字节数组地址=0xc000018078
str地址:0xc000010250,all地址:0xc000010240,all底层字节数组地址=0xc000018088
从上面输出中可以发现str和all地址一直没有变,但是all的底层字节数组地址一直在变化,这说明拼接符 + 在拼接字符串时候,会创建许多临时字符串,临时字符串意味着内存分配,指向效率不会太高。
使用 bytes.Buffer 拼接字符串 #
package main
import "bytes"
func main() {
strSlices := []string{"h", "e", "l", "l", "o"}
var bf bytes.Buffer
for _, str := range strSlices {
bf.WriteString(str)
}
print(bf.String())
}
bytes.Buffer 底层结构包含内存缓冲,最少缓冲大小是64个字节,当进行字符串拼接时候,由于利用到了缓冲,拼接效率相比拼接符 + 大大提升:
type Buffer struct {
buf []byte // 内存缓冲是字节切片类型
off int // buf已读索引,下次读取从buf[off]开始
lastRead readOp
}
func (b *Buffer) String() string {
if b == nil {
// Special case, useful in debugging.
return "<nil>"
}
return string(b.buf[b.off:])
}
注意:
bytes.Buffer是可以复用的。当进行reset时候,并不会销毁内存缓冲。
使用 strings.Builder 拼接字符串 #
package main
import "strings"
func main() {
strSlices := []string{"h", "e", "l", "l", "o"}
var strb strings.Builder
for _, str := range strSlices {
strb.WriteString(str)
}
print(strb.String())
}
strings.Builder 同 bytes.Buffer 一样都是用内存缓冲,最大限度地减少了内存复制:
type Builder struct {
addr *Builder // 用来运行时检测是否违背nocopy机制
buf []byte // 内存缓冲,类型是字节数组
}
func (b *Builder) String() string {
return *(*string)(unsafe.Pointer(&b.buf))
}
从上面可以看到 string.Builder 的 String 方法使用 unsafe.Pointer 将字节数组转换成字符串。而bytes.Buffer的 String 方法使用的 string([]byte)将字节数组转换成字符串,后者由于涉及内存分配和拷贝,相比之下它的执行效率低。
为什么bytes.Buffer的 String 方法的效率比较低,可以查看《
基础篇-切片-string类型与[]byte类型如何实现zero-copy互相转换?》。
字符串拼接基准测试 #
下面我们进行基准测试下:
// 使用拼接符拼接字符串
func BenchmarkJoinStringUsePlus(b *testing.B) {
strSlices := []string{"h", "e", "l", "l", "o"}
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
var all string
for _, str := range strSlices {
all += str
}
_ = all
}
}
}
// 复用bytes.Buffer结构
func BenchmarkJoinStringUseBytesBufWithReuse(b *testing.B) {
strSlices := []string{"h", "e", "l", "l", "o"}
var bf bytes.Buffer
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
var all string
for _, str := range strSlices {
bf.WriteString(str)
}
all = bf.String()
_ = all
bf.Reset()
}
}
}
// 使用bytes.Buffer,未进行复用
func BenchmarkJoinStringUseBytesBufWithoutReuse(b *testing.B) {
strSlices := []string{"h", "e", "l", "l", "o"}
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
var all string
var bf bytes.Buffer
for _, str := range strSlices {
bf.WriteString(str)
}
all = bf.String()
_ = all
bf.Reset()
}
}
}
// 使用strings.Builder
func BenchmarkJoinStringUseStringBuilder(b *testing.B) {
strSlices := []string{"h", "e", "l", "l", "o"}
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
all := ""
var strb strings.Builder
for _, str := range strSlices {
strb.WriteString(str)
}
all = strb.String()
_ = all
strb.Reset()
}
}
}
基准测试结果如下:
BenchmarkJoinStringUsePlus 703 1633439 ns/op 160000 B/op 40000 allocs/op
BenchmarkJoinStringUseBytesBufWithReuse 2130 471368 ns/op 0 B/op 0 allocs/op
BenchmarkJoinStringUseBytesBufWithoutReuse 1209 883053 ns/op 640000 B/op 10000 allocs/op
BenchmarkJoinStringUseStringBuilder 1830 548350 ns/op 80000 B/op 10000 allocs/op
字符串拼接效率总结 #
从上面结果可以分析得到字符串拼接效率,其中strings.Builder的效率最高,拼接字符+效率最低:
strings.Builder > bytes.Buffer > 拼接字符+
但是由于bytes.Buffer可以复用,若在需要多此执行字符串拼接的场景下,推荐使用它。