延迟执行 - defer语法 #
defer 语法支持是Go 语言中一大特性,通过 defer 关键字,我们可以声明一个延迟执行函数,当调用者返回之前开始执行该函数,一般用来完成资源、锁、连接等释放工作,或者 recover 可能发生的panic。
三大特性 #
defer延迟执行语法有三大特性:
defer函数的传入参数在定义时就已经明确 #
func main() {
i := 1
defer fmt.Println(i)
i++
return
}
上面代码输出1,而不是2。
defer函数是按照后进先出的顺序执行 #
func main() {
for i := 1; i <= 5; i++ {
defer fmt.Print(i)
}
}
上面代码输出54321,而不是12345。
defer函数可以读取和修改函数的命名返回值 #
func main() {
fmt.Println(test())
}
func test() (i int) {
defer func() {
i++
}()
return 100
}
上面代码输出输出101,而不是100或者1。
白话defer原理 #
defer函数底层数据结构是_defer结构体,多个defer函数会构建成一个_defer链表,后面加入的defer函数会插入链表的头部,该链表链表头部会链接到G上。当函数执行完成返回的时候,会从_defer链表头部开始依次执行defer函数。这也就是defer函数执行时会LIFO的原因。_defer链接结构示意图如下:
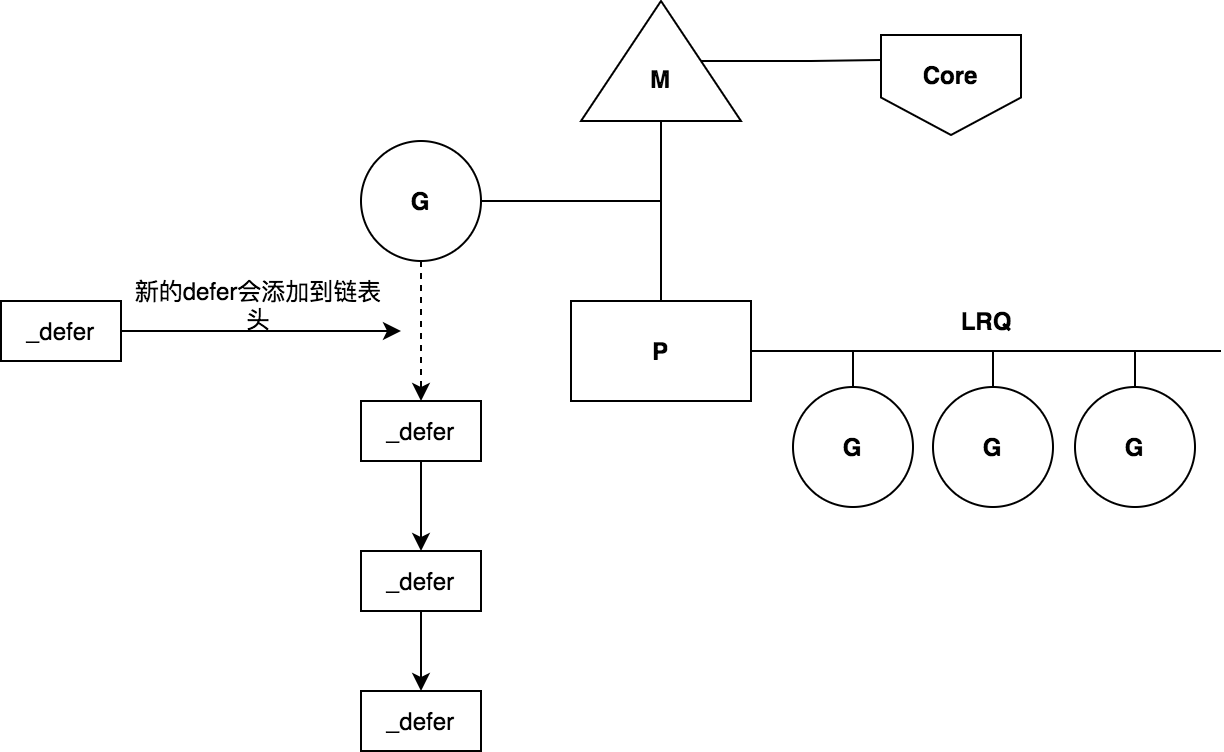
defer原理示意图
创建_defer结构体是需要进行内存分配的,为了减少分配_defer结构体时资源消耗,Go底层使用了defer缓冲池(defer pool),用来缓存上次使用完的_defer结构体,这样下次可以直接使用,不必再重新分配内存了。defer缓冲池一共有两级:per-P级defer缓冲池和全局defer缓冲池。当创建_defer结构体时候,优先从当前M关联的P的缓冲池中取得_defer结构体,即从per-P缓冲池中获取,这个过程是无锁操作。如果per-P缓冲池中没有,则在尝试从全局defer缓冲池获取,若也没有获取到,则重新分配一个新的_defer结构体。
当defer函数执行完成之后,Go底层会将分配的_defer结构体进行回收,先存放在per-P级defer缓冲池中,若已存满,则存放在全局defer缓冲池中。
源码分析 #
我们以下代码作为示例,分析defer实现机制:
package main
func main() {
defer greet("friend")
println("welcome")
}
func greet(text string) {
print("hello " + text)
}
在分析之前,我们先来看下defer结构体:
type _defer struct {
siz int32 // 参数和返回值共占用空间大小,这段空间会在_defer结构体后面,用于defer注册时候保存参数,并在执行时候拷贝到调用者参数与返回值空间。
started bool // 标记defer是否已经执行
heap bool // 标记该_defer结构体是否分配在堆上
openDefer bool // 标志是否使用open coded defer方式处理defer
sp uintptr // 调用者栈指针,执行时会根据sp判断该defer是否是当前执行调用者注册的
pc uintptr // deferprocStack或deferproc的返回地址
fn *funcval // defer函数,是funcval类型
_panic *_panic // panic链表,用于panic处理
link *_defer // 链接到下一个_defer结构体,即该在_defer之前注册的_defer结构体
fd unsafe.Pointer // funcdata for the function associated with the frame
varp uintptr // value of varp for the stack frame
framepc uintptr
}
_defer结构体中siz字段记录着defer函数参数和返回值大小,如果defer函数拥有参数,则Go会把其参数拷贝到该defer函数对应的_defer结构体后面的内存块中。
_defer结构体中fn字段是指向一个funcval类型的指针,funcval结构体的fn字段字段指向defer函数的入口地址。对应上面示例代码中就是greet函数的入口地址
上面示例代码中编译后的Go汇编代码如下, 点击在线查看汇编代码:
main_pc0:
TEXT "".main(SB), ABIInternal, $40-0
MOVQ (TLS), CX
CMPQ SP, 16(CX)
JLS main_pc151
SUBQ $40, SP
MOVQ BP, 32(SP)
LEAQ 32(SP), BP
FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
FUNCDATA $3, gclocals·9fb7f0986f647f17cb53dda1484e0f7a(SB)
PCDATA $2, $0
PCDATA $0, $0
MOVL $16, (SP)
PCDATA $2, $1
LEAQ "".greet·f(SB), AX
PCDATA $2, $0
MOVQ AX, 8(SP)
PCDATA $2, $1
LEAQ go.string."friend"(SB), AX
PCDATA $2, $0
MOVQ AX, 16(SP)
MOVQ $6, 24(SP)
CALL runtime.deferproc(SB)
TESTL AX, AX
JNE main_pc135
JMP main_pc84
main_pc84:
CALL runtime.printlock(SB)
PCDATA $2, $1
LEAQ go.string."welcome\n"(SB), AX
PCDATA $2, $0
MOVQ AX, (SP)
MOVQ $8, 8(SP)
CALL runtime.printstring(SB)
CALL runtime.printunlock(SB)
XCHGL AX, AX
CALL runtime.deferreturn(SB)
MOVQ 32(SP), BP
ADDQ $40, SP
RET
main_pc135:
XCHGL AX, AX
CALL runtime.deferreturn(SB)
MOVQ 32(SP), BP
ADDQ $40, SP
RET
需要注意的是上面汇编代码是go1.12版本的汇编代码。
从上面汇编代码我们可以发现defer实现有两个阶段,第一个阶段使用runtime.deferproc函数进行defer注册阶段。这一阶段主要工作是创建defer结构,然后将其注册到defer链表中。在注册完成之后,会根据runtime.deferproc函数返回结果进行下一步处理,若是1则说明,defer函数有panic处理,则直接跳过defer后面的代码,直接去执行runtime.deferreturn(对应就是上面汇编代码JNE main_pc135逻辑),若是0则是正常流程,则继续后面的代码(对应上面汇编代码就是 JMP main_pc84)。
第二个阶段是调用runtime.deferreturn函数执行defer执行阶段。这个阶段遍历defer链表,获取defer结构,然后执行defer结构中存放的defer函数信息。
defer注册阶段 #
defer注册阶段是调用deferproc函数将创建defer结构体,并将其注册到defer链表中。
func deferproc(siz int32, fn *funcval) {
if getg().m.curg != getg() { // 判断当前G是否处在用户栈空间上,若不是则抛出异常
throw("defer on system stack")
}
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn) // 获取defer函数参数起始地址
callerpc := getcallerpc()
d := newdefer(siz)
if d._panic != nil {
throw("deferproc: d.panic != nil after newdefer")
}
d.fn = fn
d.pc = callerpc
d.sp = sp
switch siz {
case 0:
// Do nothing.
case sys.PtrSize: // defer函数等于8字节大小(64位系统下),则直接将_defer结构体后面8字节空间
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
return0()
}
上面代码中getcallersp()返回调用者SP地址。deferproc的调用者是main函数,getcallersp()返回的SP地址指向的deferproc的return address。
getcallerpc()返回调用者PC,此时PC指向的CALL runtime.deferproc(SB)指令的下一条指令,即TESTL AX, AX。
结合汇编和deferproc代码,我们画出defer注册时状态图:
接下来,我们来看下newdefer函数是如何分配defer结构体的。
func newdefer(siz int32) *_defer {
var d *_defer
sc := deferclass(uintptr(siz)) // 根据defer函数参数大小,计算出应该使用上面规格的defer缓冲池
gp := getg()
if sc < uintptr(len(p{}.deferpool)) { // defer缓冲池只支持5种缓冲池,从0到4,若sc规格不小于5(说明defer参数大小大于64字节),
// 则无法使用缓冲池,则需从内存中分配
pp := gp.m.p.ptr() // pp指向当前M关联的P
if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil { // 若当前P的defer缓冲池为空,且全局缓冲池有可用的defer,那么先从全局缓冲拿一点过来存放在P的缓冲池中
systemstack(func() {
lock(&sched.deferlock)
for len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {
d := sched.deferpool[sc]
sched.deferpool[sc] = d.link
d.link = nil
pp.deferpool[sc] = append(pp.deferpool[sc], d)
}
unlock(&sched.deferlock)
})
}
if n := len(pp.deferpool[sc]); n > 0 {
d = pp.deferpool[sc][n-1]
pp.deferpool[sc][n-1] = nil
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
}
}
if d == nil { // 若果需要的defer缓冲池不满足所需的规格,或者缓冲池中没有可用的时候,切换到系统栈上,进行defer结构内存分配。
systemstack(func() {
total := roundupsize(totaldefersize(uintptr(siz)))
d = (*_defer)(mallocgc(total, deferType, true))
})
}
d.siz = siz
d.heap = true // 标记分配到堆上
d.link = gp._defer // 插入到链表头部
gp._defer = d
return d
}
总结下newdefer函数逻辑:
- 首先根据defer函数的参数大小,使用
deferclass计算出相应所需要的defer规格,如果defer缓冲池支持该规格,则尝试从defer缓冲池取出对应的defer结构体。 - 从defer缓冲池中取可用defer结构体时候,会首先从per-P defer缓冲池中取,若per-P defer缓冲池为空,则尝试从全局缓冲池中取一些可用defer结构体,然后放在per-P缓冲池,然后再从per-P缓冲池中取。
- 若defer缓冲池不支持该规格,或者缓冲池无可用缓冲,则切换到系统栈上进行defer结构分配。
defer缓冲池规格 #
defer缓冲池,是按照defer函数参数大小范围分为五种规格,若不在五种规格之类,则不提供缓冲池功能,那么每次defer注册时候时候都必须进行内存分配创建defer结构体:
| 缓冲池规格 | defer函数参数大小范围 | 对应per-P缓冲池位置 | 对应全局缓冲池位置 |
|---|---|---|---|
| class0 | 0 | p.deferpool[0] | sched.deferpool[0] |
| class1 | [1, 16] | p.deferpool[1] | sched.deferpool[1] |
| class2 | [17, 32] | p.deferpool[2] | sched.deferpool[2] |
| class3 | [33, 48] | p.deferpool[3] | sched.deferpool[3] |
| class4 | [49, 64] | p.deferpool[4] | sched.deferpool[4] |
defer函数参数大小与缓冲池规格转换是通过deferclass函数转换的:
func deferclass(siz uintptr) uintptr {
if siz <= minDeferArgs { // minDeferArgs是个常量,值是0
return 0
}
return (siz - minDeferArgs + 15) / 16
}
per-P级defer缓冲池与全局级defer缓冲池结构 #
per-P级defer缓冲池结构使用两个字段deferpool和deferpoolbuf构成缓冲池:
type p struct {
...
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
...
}
p结构体中deferpool数组的元素是_defer指针类型的切片,该切片的底层数组是deferpoolbuf数组的元素:
func (pp *p) init(id int32) {
...
for i := range pp.deferpool {
pp.deferpool[i] = pp.deferpoolbuf[i][:0]
}
...
}
全局级defer缓冲池保存在全局sched的deferpool字段中,sched是schedt类型变量,deferpool是由5个_defer类型指针构成链表组成的数组:
type schedt struct {
...
deferlock mutex // 由于存在多个P并发的从全局缓冲池中获取defer结构体,所以需要一个锁
deferpool [5]*_defer
...
}
defer执行阶段 #
当函数返回之前,Go会调用deferreturn函数,开始执行defer函数。总之defer流程可以简单概括为:Go语言通过先注册(通过调用deferproc函数),然后函数返回之前执行defer函数(通过调用deferreturn函数),实现了defer延迟执行功能。
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
if d == nil { // defer链表为空,直接返回。deferreturn是一个递归调用,每次调用都会从defer链表弹出一个defer进行执行,当defer链表为空时候,说明所有defer都已经执行完成
return
}
sp := getcallersp()
if d.sp != sp { // defer保存的sp与当前调用deferreturn的调用者栈顶sp不一致,则直接返回
return
}
switch d.siz {
case 0:
case sys.PtrSize: // 若defer参数大小是8字节,则直接将defer参数复制给arg0
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default: // 否则进行内存移动,将defer的参数复制到arg0中,此后arg0存放的是延迟函数的参数
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}
deferreturn函数通过jmpdefer实现递归调用,jmpdefer是通过汇编实现的,jmpdefer函数完成两个功能:调用defer函数和deferreturn再次调用。deferreturn递归调用时候,递归终止条件有两个:1. defer链表为空。2. defer保存的sp与当前调用deferreturn调用者栈顶sp不一致。第一个条件很好了解,第二个循环终止条件存在原因,我们稍后探究。
我们需要理解arg0这个变量用途。arg0看似是deferreturn的参数,实际上是用来存储延迟函数的参数。
在调用jmpdefer之前,会先调用freedefer将当前defer结构释放回收:
func freedefer(d *_defer) {
if d._panic != nil { // freedefer调用时_panic一定是nil
freedeferpanic() // freedeferpanic作用是抛出异常:freedefer with d._panic != nil
}
if d.fn != nil { // freedefer调用时fn一定已经置为nil
freedeferfn() // freedeferfn作用是抛出异常:freedefer with d.fn != nil
}
if !d.heap { // defer结构不是在堆上分配,则无需进行回收
return
}
sc := deferclass(uintptr(d.siz)) // 根据defer参数和返回值大小,判断规格,以便决定放在哪种规格defer缓冲池中
if sc >= uintptr(len(p{}.deferpool)) {
return
}
pp := getg().m.p.ptr()
if len(pp.deferpool[sc]) == cap(pp.deferpool[sc]) { // 当前P的defer缓冲池已满,则将P的defer缓冲池defer取出一般放在全局defer缓冲池中
systemstack(func() {
var first, last *_defer
for len(pp.deferpool[sc]) > cap(pp.deferpool[sc])/2 {
n := len(pp.deferpool[sc])
d := pp.deferpool[sc][n-1]
pp.deferpool[sc][n-1] = nil
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
if first == nil {
first = d
} else {
last.link = d
}
last = d
}
lock(&sched.deferlock)
last.link = sched.deferpool[sc]
sched.deferpool[sc] = first
unlock(&sched.deferlock)
})
}
// 重置defer参数
d.siz = 0
d.started = false
d.sp = 0
d.pc = 0
d.link = nil
pp.deferpool[sc] = append(pp.deferpool[sc], d) // 将当前defer放入P的defer缓冲池中
}
我们来看下jmpdefer实现:
TEXT runtime·jmpdefer(SB), NOSPLIT, $0-16
MOVQ fv+0(FP), DX # DX寄存器存储jmpdefer第一个参数fn,fn是funcval类型指针
MOVQ argp+8(FP), BX # BX寄存器存储jmpdefer第二个参数,该参数是个指针类型,指向arg0
LEAQ -8(BX), SP # 将BX存放的arg0的地址减少8,获取得到调用deferreturn时栈顶地址(此时栈顶存放的是deferreturn的return address),最后将该地址存放在SP寄存器中
MOVQ -8(SP), BP # 重置BP寄存器
SUBQ $5, (SP) # 此时SP寄存器指向的是deferreturn的return address。该指令是将调用deferreturn的return address减少5,
# 而减少5之后,return adderss恰好指向了`CALL runtime.deferreturn(SB)`,这就实现了deferreturn递归调用
MOVQ 0(DX), BX # DX存储的是fn,其是funcval类型指针,所以获取真正函数入口地址需要0(DX),该指令等效于BX = Mem[R[DX] + 0]。
# 寄存器逻辑操作不了解的话,可以参看前面Go汇编章节
JMP BX # 通过JMP指令调用延迟函数
从上面代码可以看出来,jmpdefer通过汇编更改了延迟函数调用的return address,使return address指向deferreturn入口地址,这样当延迟函数执行完成之后,会继续调用deferreturn函数,从而实现了deferreturn递归调用。deferreturn和jmpdefer最后实现的逻辑的伪代码如下:
function deferreturn() {
var arg int
for _, d := range deferLinkList {
arg = d.arg
d.fn(arg)
deferreturn()
}
}
画出deferreturn调用内存和栈的状态图,帮助理解:
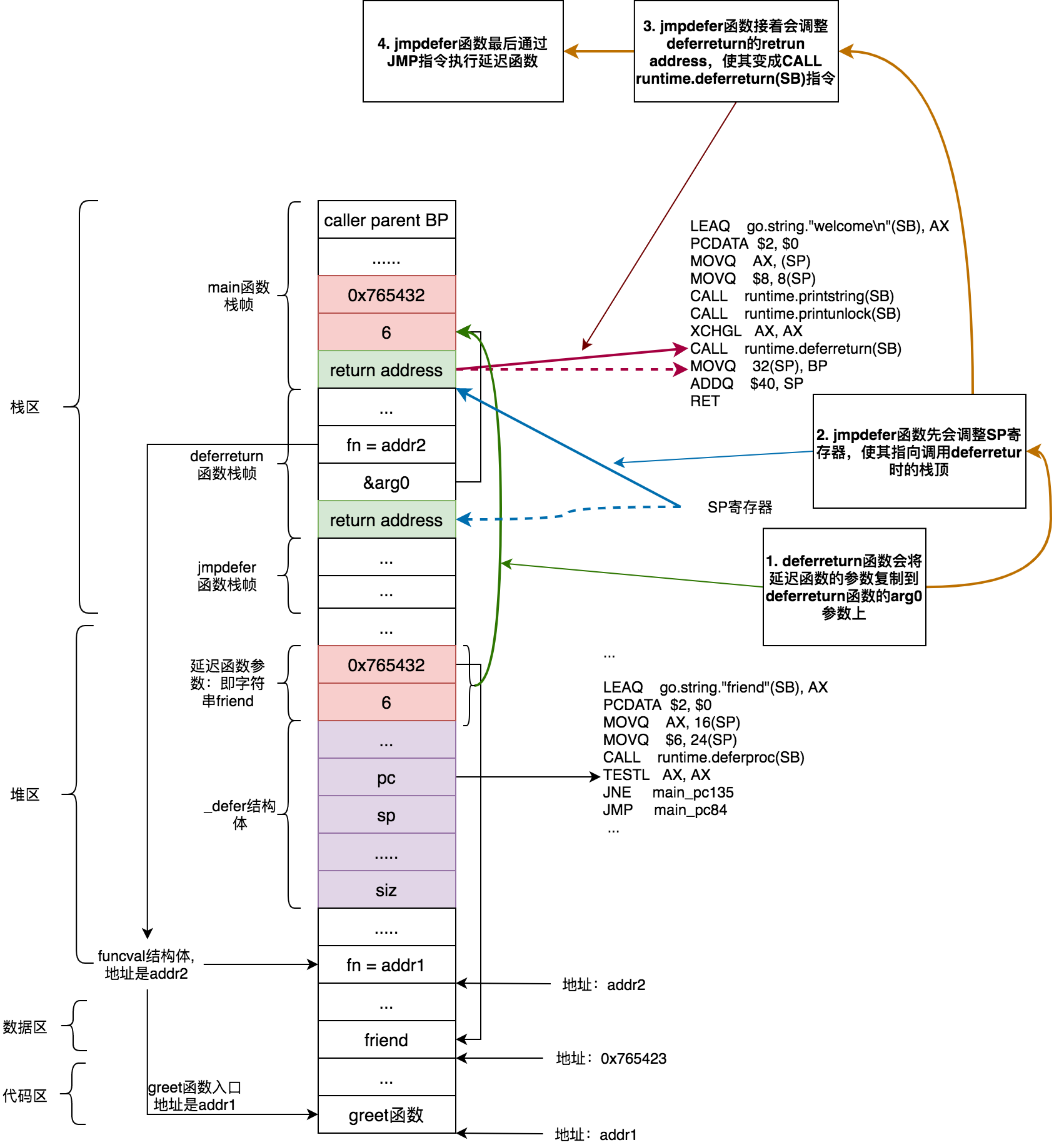
最后我们来探究一下deferreturn第二个终止条件,考虑下面的场景:
func A() {
defer B()
defer C()
}
func C() {
defer D()
}
将上面代码转换成成底层实现的伪代码如下:
func A() {
deferproc(B) // 注册延迟函数B
deferproc(C) // 注册延迟函数C
deferreturn() // 开始执行延迟函数
}
func C() {
deferproc(D) // 注册延迟函数C
deferreturn() // 开始执行延迟函数
}
当调用A函数的deferreturn函数时,会从defer链表中取出延迟函数C进行执行,当执行C函数时,其内部也有一个defer函数,C函数最后也会调用deferreturn函数,当C函数中调用deferreturn函数时,defer链表结构如下:
sp指向C的栈顶 sp指向A的栈顶
| |
| |
v v
g._defer ---------> D --------> B
当C中的deferreturn执行完defer链表中延迟函数D之后,开始执行B的时候,由于B的sp指向的是A的栈顶,不等于C的栈顶,此时满足终止条件2,C中的deferreturn会退出执行,此时A的deferreturn开始继续执行(A的deferreturn调用其C的deferreturn函数,相当于一个大循环里面套一个小循环,现在是小循环退出了,大循环还是会继续的),此时由于B的sp指向就是A的栈顶,B函数会执行。
deferreturn循环终止第二个条件就是为了解决诸于此类的场景。
优化历程 #
上面我们分析的代码中defer结构是分配到堆上,其实为了优化defer语法性能,Go在实现过程可能会将defer结构分配在栈上。我们来看看Go各个版本对defer都做了哪些优化?
package main
func main() {
defer greet()
}
func greet() {
print("hello")
}
我们以上面代码为例,看看其在go1.12、go1.13、go1.14这几个版本下的核心汇编代码:
|
|
go1.12版本中通过调用 runtime.deferproc 函数,将defer函数包装成 _defer 结构并注册到defer链表中,该 _defer 结构体是分配在堆内存中,需要进行垃圾回收的。
|
|
go1.13版本中通过调用 runtime.deferprocStack 函数,将defer函数包装成 _defer 结构并注册到defer链表中,该 _defer 结构体是分配在栈上,不需要进行垃圾回收处理,这个地方就是go1.13相比go1.12所做的优化点。
|
|
go1.14版本不再调用deferproc/deferprocStack 函数来处理,而是在 return 返回之前直接调用该 defer函数(即inline方式),性能相比go1.13又得到进一步提升,go官方把这种处理方式称为open-coded defer。实际上go1.14中禁止优化和内联之后,defer函数其底层实现方式就和go1.13一样了。
需要注意的是 open-coded defer 使用是有限制的,它不能用于for循环中的defer函数,还有就是defer的数量也是有限制的,
最多支持8个defer函数,对于for循环或者数量过的defer,将使用deferproc/deferprocStack方式实现。关于 open-coded defer 设计细节可以参见官方设计文档:
Proposal: Low-cost defers through inline code, and extra funcdata to manage the panic case
此外 open-coded defer 虽大大提高了 defer 函数执行的性能,但 panic 的 recover 的执行性能会大大变慢,这是因为 panic 处理过程中会扫描 open-coded defer 的栈帧。具体参见open-coded defer的
代码提交记录。open-coded defer带来的好处的是明显,毕竟panic是比较少发生的。
go1.14也增加了 -d defer 编译选项,可以查看defer实现时候使用哪一种方式:
go build -gcflags="-d defer" main.go
总结一下defer优化历程:
| 版本 | 优化内容 |
|---|---|
| Go1.12及以前 | defer分配到堆上,是heap-allocated defer |
| Go1.13 | 支持在栈上分配defer结构,减少堆上分配和GC的开销,是stack-allocated defer |
| G01.14 | 支持开放式编码defer,不再使用defer结构,直接在函数尾部调用延迟函数,是open-coded defer |